Article Text

Abstract
Background Several studies have examined the effects of sample selection on the exposure–outcome association estimates in cohort studies, but the reasons why this selection may induce bias have not been fully explored.
Aims To investigate how sample selection of the web-based NINFEA birth cohort may change the confounding patterns present in the source population.
Methods The characteristics of the NINFEA participants (n=1105) were compared with those of the wider source population—the Piedmont Birth Registry (PBR)—(n=36 092), and the association of two exposures (parity and educational level) with two outcomes (low birth weight and birth by caesarean section), while controlling for other risk factors, was studied. Specifically the associations among measured risk factors within each dataset were examined and the exposure–outcome estimates compared in terms of relative ORs.
Results The associations of educational level with the other risk factors (alcohol consumption, folic acid intake, maternal age, pregnancy weight gain, previous miscarriages) partly differed between PBR and NINFEA. This was not observed for parity. Overall, the exposure–outcome estimates derived from NINFEA only differed moderately from those obtained in PBR, with relative ORs ranging between 0.74 and 1.03.
Conclusions Sample selection in cohort studies may alter the confounding patterns originally present in the general population. However, this does not necessarily introduce selection bias in the exposure–outcome estimates, as sample selection may reduce some of the residual confounding present in the general population.
- Sample selection
- selection bias
- residual confounding
- web-based studies
- cohort studies
- directed acyclic graph
- biostatistics
- epidemiology
- growth
- longitudinal studies
- medical statistics
- sport
- nutrition
- diet
Statistics from Altmetric.com
- Sample selection
- selection bias
- residual confounding
- web-based studies
- cohort studies
- directed acyclic graph
- biostatistics
- epidemiology
- growth
- longitudinal studies
- medical statistics
- sport
- nutrition
- diet
Introduction
Cohort studies are frequently conducted in selected populations, with the study subjects either self-selected or selected according to some prespecified criteria. The consequence of this selection process on the internal validity of the exposure–outcome associations has been defined as selection bias,1 or a special case of confounding,2 and have been extensively discussed in the literature. In particular, the use of self-selected or restricted populations for cohort studies may introduce bias if the selection mechanism alters the original (population-level) associations between the exposure(s) of interest and the other risk factor(s) for the outcome, therefore changing the strength and, possibly, the direction of confounding.1 ,2
Several papers have compared the characteristics of participants in cohort studies with those of non-participants to assess the representativeness of the study sample.3–11 Two of these have also evaluated the potential effects of the selection process on the exposure–outcome estimates of interest within the context of birth cohorts.4 ,5 However, none of these earlier studies have specifically explored the mechanisms through which bias can be induced by the sample selection process.
In this paper, we aim to examine these mechanisms, focusing on comparisons of the confounding patterns (ie, the associations among all outcome risk factors, including the exposure of interest) for the associations of interest in the general population and in the selected sample.
We will use data from the NINFEA study, an established ongoing web-based birth cohort, in which study subjects enrol through the internet.12 It started as a pilot study in the city of Turin (capital of the Piedmont Region, Italy) but it has been extended, since December 2007, to the rest of the country. Recruitment occurs during pregnancy, when the women are informed about the study and may choose to register on the study website. The existence of the study is advertised at hospitals and family clinics of selected areas and through websites of interest for pregnant women. Undoubtedly the NINFEA participants are a selected sample of the source population, with participation strongly associated with socioeconomic factors.12
We decided to investigate the impact of the changes in the confounding patterns due to the sample selection on the exposure–outcome associational estimates observed in NINFEA, by comparing the characteristics of the study participants with those of the wider source population (the Piedmont Birth Registry, PBR). Our specific objectives were: (1) to explore the frequency of selected variables in PBR and NINFEA; (2) to compare the associations between the exposure of interest and the other risk factors available in the sample and in the source population; (3) to formally compare the exposure–disease association estimates obtained in PBR and in NINFEA; and (4) to examine alternative potential mechanisms leading to these results using directed acyclic graphs (DAGs).13–15
Material and methods
Data
We used the PBR data for the period 2005–08, which includes 145 885 pregnancy records, created by midwives at the time of the delivery.16 Compulsory computerised birth registration was established in the whole of Italy in 2001. In Piedmont it is of particularly high quality and completeness.17 Records from PBR were linked to those from the NINFEA study (data downloaded in July 2010). The latter included 1547 singleton pregnancies after exclusion of births occurring after December 2008 and those occurring outside Piedmont. The date of birth of the mother, the date of birth and the sex of the child, and the hospital and ward where the delivery occurred were used as (deterministic) linkage key variables. The linkage was successful for 1298 (84%) births. We further excluded births with gestational age earlier than the 25th or later than the 44th week, as well as those with implausible birth weights in the PBR data. This led to reducing the original dataset to 145 496 records, 1295 of which were linked to NINFEA. Since most of the NINFEA births occurred in the city of Turin and most of their parents were Italian, we further restricted the analyses to children born in Turin from Italian parents to avoid strata with sparse data. Thus the final PBR dataset was substantially reduced (n=36 092), unlike the NINFEA dataset (n=1105).
The PBR holds information on maternal and child/delivery characteristics. In particular, data on parents' age, educational level and occupation were available, together with maternal smoking and alcohol consumption during pregnancy as well as pregnancy weight gain and intake of folic acid. Information on the reproductive history of the mother (ie, parity, previous miscarriages and use of infertility treatment) and information on reproductive outcomes (ie, type, gestational age, birth size) is also recorded in the PBR.
Statistical analysis
In order to assess the impact of selection on the estimate of an effect of interest, we examined two outcomes: low birth weight for gestational age (LBW, defined as birth weight lower than the 20th percentile of the internally gestational age-standardised distribution) and birth by caesarean section.
We then selected the main potential risk factors recorded in the PBR for these two outcomes and examined their prevalence ORs of participation in NINFEA. Self-selection or cohort restriction may introduce non-negligible bias in cohort studies when the exposure–selection OR is ≥2 or ≤0.5.18 In our study, only parity and maternal education satisfied this criterion. Thus, we chose these two main predictors of participation as the exposures of interest and studied them in association with the two outcomes, while we treated the other variables—maternal age, weight gain during pregnancy, consumption of folic acid, alcohol during pregnancy and history of previous miscarriages—as potential confounders. Maternal smoking and use of infertility treatment were not considered further as potential confounders because of their low population prevalence.
The analyses involved: (1) estimating the Prevalence ORs (POR); (2) investigating the effects on the exposure–potential confounder associations of restricting the analyses to the selected sample; and (3) for each outcome separately, formally comparing the estimated exposure–outcome associations obtained in the selected sample and in the original population.
For simplicity, all continuous variables were dichotomised. Namely, low pregnancy weight gain was defined as a weight gain lower than the 20th percentile in PBR (10 kg); young maternal age as lower than the PBR median (33 years); and maternal parity as nulliparous (ie, no previous live births) versus parous. Logistic regression analyses were performed to study associations, leading to estimated ORs and corresponding 95% CIs. For the two outcomes of interest, both the crude and the fully adjusted (by all potential confounders) ORs for the two exposures were estimated in each dataset. Their formal comparison was performed in terms of relative ORs—that is, the ratios of the NINFEA-based OR over the PBR-based OR, with CIs obtained as in Nohr et al.5 We focused on ORs in line with previous publications on self-selection bias4 ,5 although results were substantially unchanged when based on risk ratios.
Results
Of 36 092 delivery records included in the PBR dataset, 1105 were participants of the NINFEA cohort—that is, a participation proportion of 3.1%.
Predictors of participation
The two exposures of interest (maternal education and parity) and most of the seven other potential selected risk factors were associated with participation in NINFEA. Low parity, high educational level and non-smoking during pregnancy were the strongest predictors in both crude and mutually adjusted analyses (table 1). There was some evidence of effect modification between maternal education and age (p<0.001), with the OR of participation for high education level increasing from 1.9 among older women (>32 years) to 3.4 among younger ones (≤32 years). When this interaction was included in the model the adjusted ORs for the other factors did not change (data not shown).
Frequency distribution of potential risk factors and crude and adjusted ORs of participation into the NINFEA cohort study
Associations between exposures and risk factors
Parity
There is a substantial difference in the distribution of parity across the two datasets: about 45% of PBR records involved women with parity greater than 0, compared with about 20% in the NINFEA study (table 1).
In the PBR population, parity was associated with almost all the potential confounders, although ORs were greater than 1.5 only for maternal age and history of previous miscarriages (table 2). Findings in NINFEA were generally similar, although the association between maternal age and parity was slightly stronger (OR=3.17; 95% CI 2.27 to 4.45 in NINFEA vs OR=2.45; 95% CI 2.35 to 2.56 in PBR) (table 2).
Crude associations (OR and 95% CI) of parity (parous vs nulliparous) with other potential risk factors in the Piedmont Birth Registry (PBR) population and among the NINFEA participants
Maternal education
Maternal education also has a different distribution in the two datasets, with more educated women contributing to NINFEA (table 1). In PBR, maternal education was strongly associated with maternal age (OR=2.09, 95% CI 1.97 to 2.21) while in NINFEA the association with maternal age was weaker (OR=1.22, 95% CI 0.95 to 1.57), and that with folic acid intake was stronger (table 3).
Crude associations (OR and 95% CI) of maternal education with other potential risk factors in the Piedmont Birth Registry (PBR) population and among the NINFEA participants
Associations between exposures and outcomes
Caesarean section
The upper left side of table 4 reports the crude ORs of caesarean section for parity and maternal education, obtained in PBR and NINFEA. The estimates obtained from NINFEA are closer to the null value than those obtained from PBR, as reflected by relative ORs below 1.0. When the ORs were adjusted for all other potential risk factors, the estimates from PBR and NINFEA were both reduced to a similar extent, leading to substantially unchanged relative ORs (table 4).
Crude and fully adjusted ORs for the effect of parity and maternal education on caesarean section and LBW in the birth registry population and in the NINFEA cohort, together with the corresponding relative ORs
Low birth weight for gestational age
The crude ORs of LBW for parity were reasonably similar when estimated in PBR and NINFEA (relative OR=0.79; table 4). When these estimates were adjusted for potential confounders, their relative sizes did not change markedly (relative OR=0.74, 95% CI 0.49 to 1.13). However, residual confounding should not be discounted, as information on a number of known risk factors for LBW was not available, and it is therefore hard to predict whether the adjusted OR estimate of 0.43 found in NINFEA is more or less affected by residual confounding than that of 0.58 found in PBR.
High level of education was found to be inversely associated with LBW. The ORs estimated in PBR and in NINFEA were equal, leading to crude and adjusted relative ORs of 1.0 (table 4).
DAGs illustrating the effect of changes in the confounding pattern due to sample selection on bias
In a web-based cohort study, such as NINFEA, the sample selection process is driven by two main mechanisms: (1) the restriction of the source population to internet users; and (2) the decision to participate. For simplicity we will focus here only on the latter mechanism; however, this line of reasoning can be generalised to any other selection mechanism.
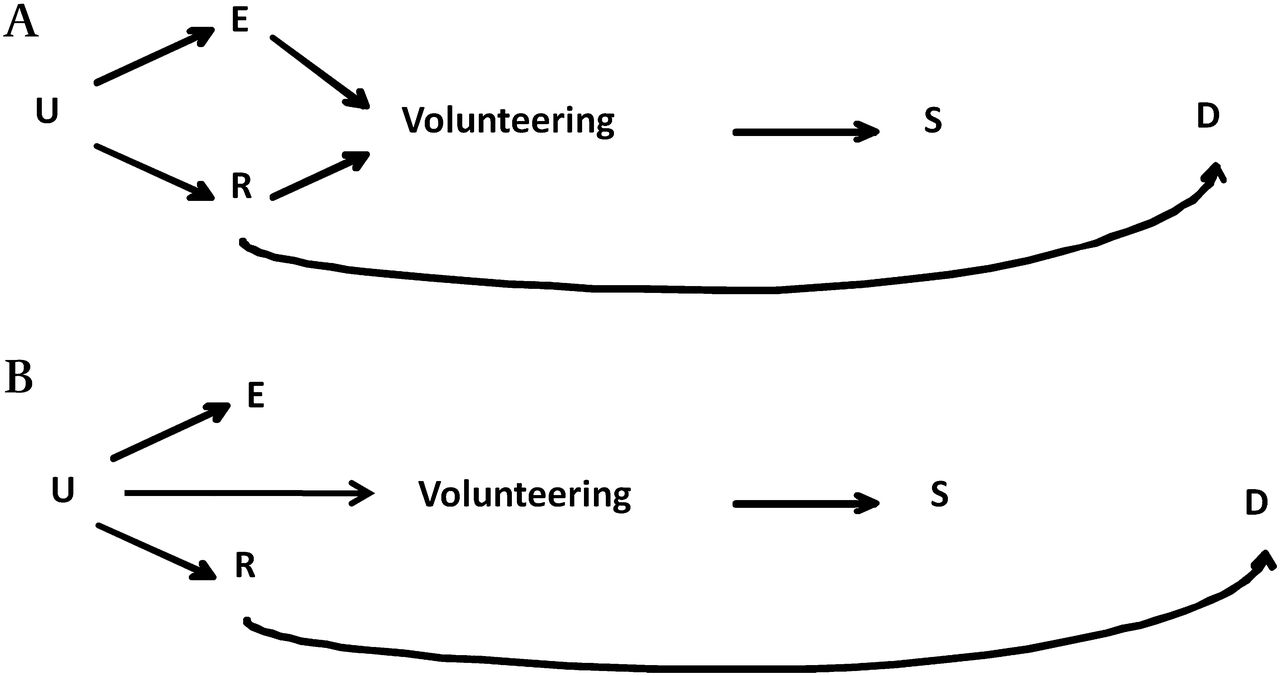
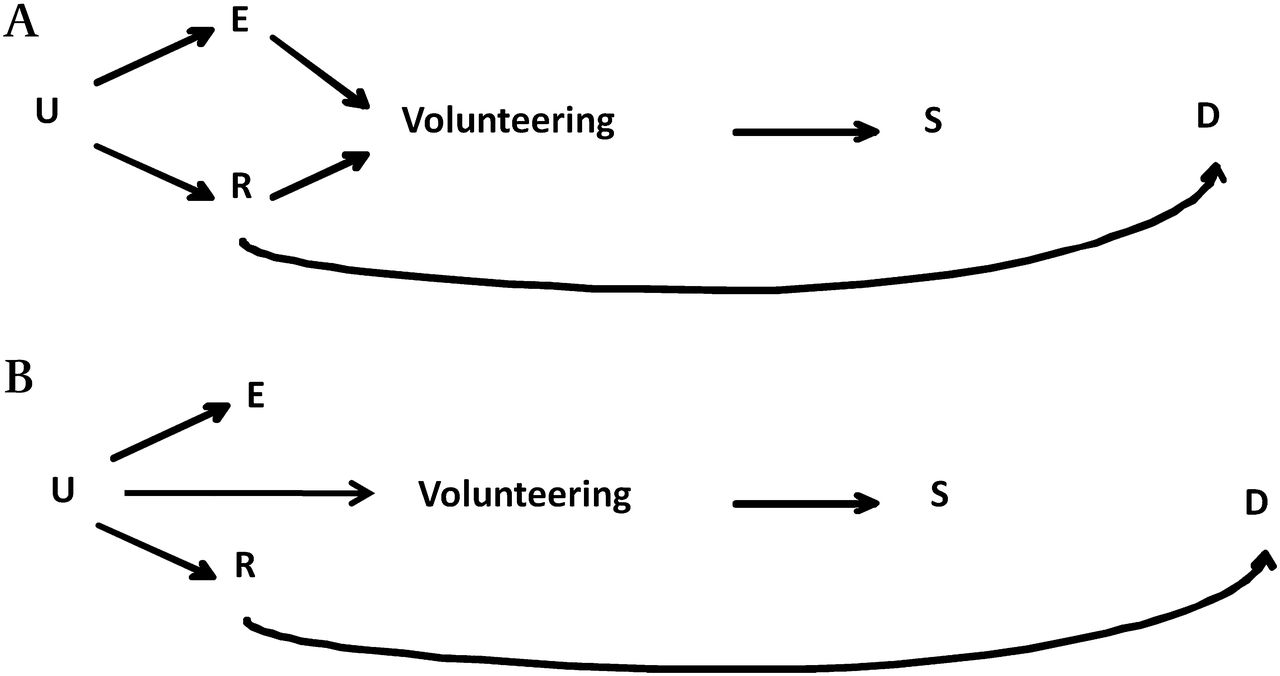
Conditioning on volunteers may either induce or attenuate bias depending on the population-level relationships between the exposure of interest and the other risk factors. The two main scenarios that may arise are illustrated, using DAGs, in figures 1 and 2, where E indicates the exposure of interest, R is a risk factor for the disease of interest D, U1 and U2 are other unmeasured variables, and S is an indicator of selection into the sample. For simplicity, we assume no causal effect of the exposure on the outcome, no interaction between E and R in their effect on D, and that no mediator on the E–D pathway can influence selection. In the first scenario (figure 1), E and R are independent in the general population and both affect the likelihood of being selected (through volunteering), either directly (figure 1A) or as proxy of some other factors U1 and U2 (figure 1B). Restricting on S induces an association between E and R, making R a confounder in the subset of the participants. Thus selection is likely to induce bias in the exposure–disease association unless the back-door path E–R–D is blocked, for example by adjustment. In our data, this may be the case of maternal education (E) and folic acid intake (R), which are both associated with participation (table 1). These variables are independent in the PBR population (OR=1.01 in table 3), but become associated among the NINFEA participants (OR=1.44 in table 3).

Diagram of a cohort where subjects volunteer to participate. (A) In the population the exposure of interest (E) is independent of the disease risk factor (R) and both affect the likelihood of being selected into the sample (S), through volunteering. (B) (E) is independent of the disease risk factor (R) and both affect the likelihood of S (through volunteering) as a proxy of some other factors (U).
{kind=link}
{kind=link}
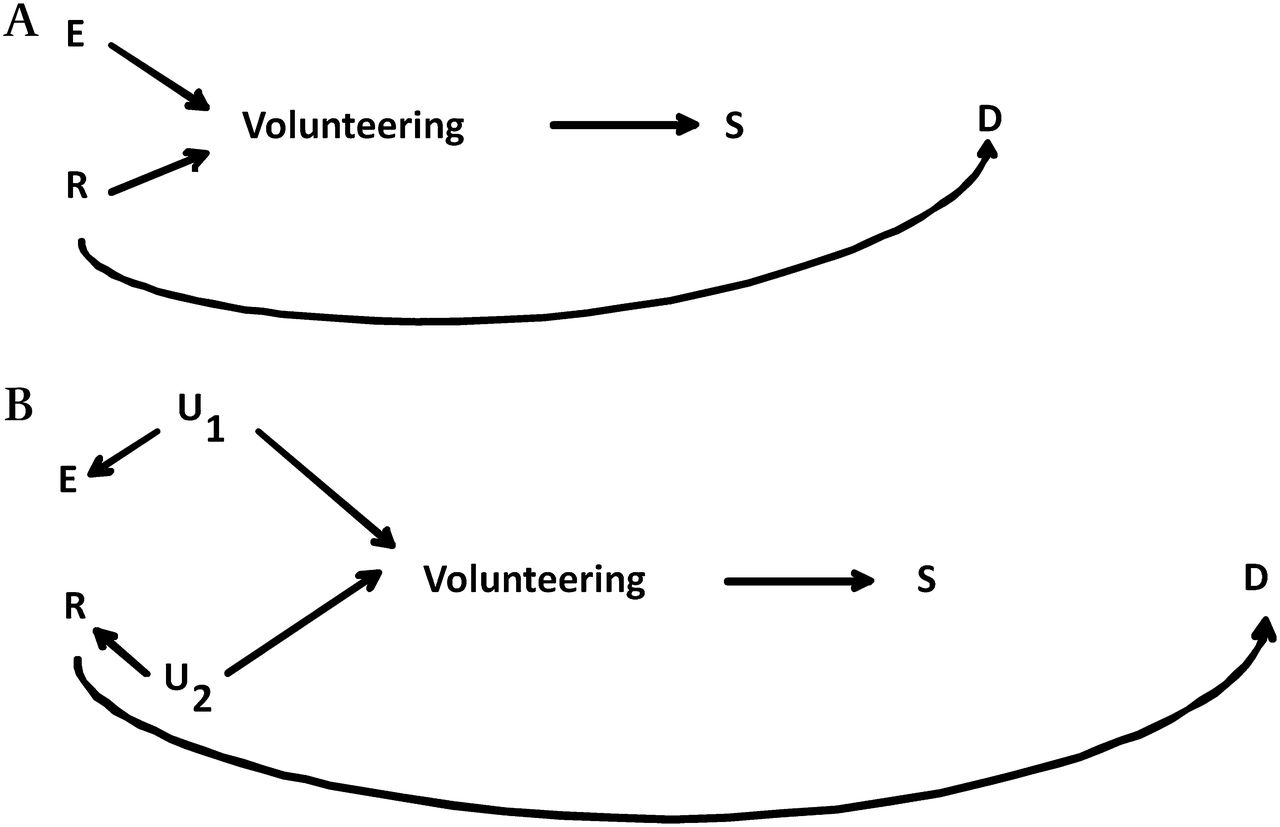
Diagram of a cohort where subjects volunteer to participate. (A) In the population the exposure of interest (E) and the disease risk factor (R) are associated between each other as they share a common cause of some other factors (U), and they both affect the probability of participation (S), through volunteering. (B) In the population E and R share a common cause U, and U also affects the probability of volunteering.
In the second scenario (figure 2), E and R still affect the probability of participation, but now they share a common cause U (figure 2A), implying that R is already a confounder in the general population. Under this scenario the selection process can either induce or attenuate the bias, depending both on the strength and direction of the E–R association present in the general population and of the equivalent associations within the restricted sample defined by S. Although there are a number of exceptions,19 typically when two variables influence a third one in the opposite (same) direction, conditioning on the latter leads to a positive (negative) spurious association between the first two variables.13 ,18 It follows that when E and R are, for example, positively associated in the general population, selection is likely to attenuate the bias in an unadjusted estimate of the E–D association, if E and R have a qualitatively similar effect on the probability of volunteering. The opposite would happen if they had a qualitatively opposite effect on selection. We observed this pattern in our data. Let us consider the case of parity and maternal age, which are, respectively, negatively (OR=0.32) and positively (OR=1.30) associated with participation in NINFEA (table 1) while they are positively associated in the source population (OR=2.45; table 2). When analyses are restricted to the NINFEA data, the OR for their association increases to 3.17 (table 2). In contrast, the OR for the association between maternal education and maternal age, which are both positively associated with the probability of being selected (table 1)—decreased from 2.09 in PBR to 1.22 in NINFEA (table 3). As a consequence the OR for maternal education and caesarean section, for example, estimated adjusting for all other known risk factors except for maternal age, shows a smaller degree of residual confounding than that estimated from PBR. In particular the estimate derived from PBR increases from 1.07 (95% CI 1.01 to 1.14; table 4) when fully adjusted, to 1.14 (95% CI 1.08 to 1.22) when adjusted for all measured risk factors except for maternal age. The corresponding figures from NINFEA are 0.97 (95% CI 0.69 to 1.35; table 4) and 0.98 (95% CI 0.70 to 1.37), which are almost identical.
A special and relevant case is when the association in the population between E and R is due to a common unmeasured cause U, which also influences the probability of volunteering (figure 2B). Under this scenario, conditioning on S may imply a partial conditioning on U and a consequent attenuation of the confounding bias due to E–U–R–D. For example, if socioeconomic condition (U) is a determinant of smoking (E) and drinking (R) in pregnancy as well as of volunteering, restricting the analyses to the selected sample is equivalent to adjusting for a proxy of socioeconomic status. As a consequence the association between smoking and drinking would be attenuated in the selected sample.
Discussion
In this paper we have investigated whether the patterns of confounding present in NINFEA differed from the ones observed in the whole PBR population, and assessed the extent of selection bias affecting the NINFEA study, by comparing the exposure–outcome associational estimates derived from these two datasets.
Undoubtedly the NINFEA participants differ substantially from the general population. Consistent with what has been found in other birth cohort studies, participating mothers are more likely to take folic acid during pregnancy, to be nulliparous, to be less likely to smoke,4 ,5 and are on average older at delivery and with a higher educational level3 than in the general population.
Several papers have examined the baseline characteristics of participants in cohort studies in comparison with those of non-participants to assess the representativeness of the study sample,3–11 but none of them has specifically explored the mechanisms through which the extent of bias in the exposure–outcome estimates may be related to changes in the confounding patterns for the associations of interest. We have focused on the associations between the exposures of interest and the other risk factors for which we had information both in the general population, and in the selected sample. The extent of the bias affecting the exposure–disease association estimates in NINFEA was then assessed in the light of the potential effect of changes in the confounding patterns due to the sample selection.
Our findings indicate that the main variables to be controlled to minimise bias identified for the general population may not be the most important or relevant ones for analyses involving a cohort study of a selected subgroup of the general population. For example, our data showed that the estimated associations between maternal education and the other potential risk factors in NINFEA differed from those in PBR (table 3). Similar reasoning would apply to the role of unknown confounders, and therefore it is not possible to predict whether estimates based on a selected cohort would be more or less biased than those based on the equivalent population-based cohort. In fact, consistent results between the source population and the selected cohorts would argue in favour of similar confounding patterns or absence of confounding. Analogously, if results differ, this may imply that either residual confounding is an important issue for the exposure–disease association of interest or that the distribution of some unknown modifiers of this association differs between the selected and the population-based cohort. Obviously, these two scenarios are not mutually exclusive.
In order to understand whether the estimates derived from the selected sample are more or less valid than those obtained in the general population, it would be necessary to distinguish between the scenarios depicted in figures 1 and 2. In other words, it would be necessary to know whether the exposure (E) and the potential unmeasured confounder (R) are already associated in the general population or become associated in the selected sample. In some cases, expert opinion could be invoked to assess the likelihood of one scenario over the other. However, there is little published data on E–R associations in different populations but associations among risk factors are very likely.20
The findings presented here are based on a relative small study size, as our analyses of the NINFEA cohort include only 1105 subjects; thus, the precision of some estimates was low. In particular the numbers were too small to explore the effects of some important variables, such as maternal smoking during pregnancy and use of infertility treatment. Another limitation of this study concerns the lack of data on important risk factors and the consequent potential effect of residual confounding which may partly explain the observed differences in the estimated effects.
Taking this into consideration, our study nevertheless suggests that the estimates derived from NINFEA do not differ considerably from those obtained from PBR, with relative ORs ranging between 0.74 and 1.03. In agreement with previous studies investigating the effect of non-participation in birth cohort studies,4 ,5 we have shown that even in a web-based birth cohort, selection does not induce substantial bias in the exposure–outcome associations we investigated. It is however important to consider the expected magnitude of these effects of interest when evaluating potential biases: when this is really small, even a moderate bias becomes relevant.
It should also be noted that this study only concerns baseline selection in cohort studies, which is by definition independent of the outcome. Our results cannot be extrapolated to the selection arising because of informative drop-outs, or to other epidemiological study designs, such as cross-sectional studies or case–control studies, where the disease/outcome status may affect participation.
In conclusion, possible differences in the estimates of the exposure–outcome associations between a selected and a population-based cohort reflect changes in the confounding patterns due to the sample selection process. Therefore, unless all relevant confounders in the two cohorts are known and measured, it is not possible to predict whether estimates based on a cohort selected at baseline would be more or less biased than those based on the equivalent population-based cohort, as sample selection might also reduce the confounding already present in the general population.
What is already known on this subject
-
Several papers have examined the baseline characteristics of participants in cohort studies in comparison with those of non-participants and some have also evaluated the potential effects of the selection process on the exposure–outcome estimates of interest.
-
However none of these studies have specifically explored the mechanisms through which bias can be induced by the sample selection process.
What this study adds
-
By comparing the confounding patterns and the exposure–outcome associations between the general population and the NINFEA internet-based birth cohort study sample, we found that possible differences in the estimates of the exposure–outcome associations between a selected and a population-based cohort reflect changes in the confounding patterns due to the sample selection process.
-
Therefore, unless all relevant confounders in the two cohorts are known and measured, it is not possible to predict whether estimates based on a cohort selected at baseline would be more or less biased than those based on the equivalent population-based cohort, as sample selection might also reduce the confounding already present in the general population.
References
Footnotes
-
Funding This work was supported by Compagnia SanPaolo/FIRMS, the Piedmont Region, the Italian Ministry of University and Research (MIUR), the Italian Association for Research on Cancer (AIRC) and the Massey University Research Fund (MURF). The Centre for Public Health Research is supported by a Programme Grant from the Health Research Council of New Zealand.
-
Competing interests None.
-
Ethics approval The study was approved by the Ethical Committee of the San Giovanni Battista Hospital—A.S.O. C.T.O./C.R.F./Maria Adelaide, Turin, Italy.
-
Provenance and peer review Not commissioned; externally peer reviewed.